Coherent Noise Generation: First Principles
Randomness plays a key roll in many graphics and simulation techniques. Variations in behaviour can make simulations feel more alive. Randomised worlds can keep exploration alive in games.
Often a simple call to your language’s equivalent to rand for will suffice; perhaps modified by a non-uniform distribution. But what if we wanted a smooth transition between generated values? A function of position? Infinite and tilable but non-repeating patterns?
These properties can be satisfied by a 'coherent noise' function which maps an n-dimensional vector to a single value. They have the additional property that small changes changes in inputs tend to have small changes in the output.
You may have seen such noise functions in many areas of computer graphics, particularly texture synthesis and simple terrain generation.
- Natural texture generators for 'clouds', 'wood', 'marble' and others are generally a 2D fractal gradient noise
- Terrain generation in various voxel games like Minecraft, albeit in a modified form.
- famously, the planet terraforming scenes in `Star Trek II' (amongst countless other films)
The typical algorithm is as follows:
- Map some input point to value(s) through a 'basis' function .* Combine values from a collection of `nearby' points at integral positions
- Sum a number of successive iterations of the basis function .* Modify the input frequency and output scaling each iteration
- Post-process an output region for consistency/aethestics
I am currently evaluating a collection of these algorithms for the procedural terrain components of `Edict'. The remainder of this post may include some level of bias towards heightfield generation.
Basis Functions
At the core of a noise algorithm is the basis function. It provides a mapping between the input vector and the output scalar. This mapping must be deterministic, but as with rand and friends, a 'seed' value may be supplied so we can vary the outputs when needed.
There are two major categories of noise function I see in popular use:
- lattice
- Values are generated for points at regular intervals and the nearest values to the input point are interpolated, weighted by distance. Lattice noise functions include 'value' noise, and the gradient noise functions 'Perlin', 'simplex', and 'wavelet' noise.
- point
- Values are related to the distances between the input point and a set of pseudo-randomly distributed points. Worley (aka Voronoi or Cellular) noise is the main contender here.
Each basis function comes with efficiency and quality tradeoffs.
Value Noise
The simplest method is to assign one random scalar to each integral coordinate (the red points). Any deterministic method can be used to generate these values.

Evaluation at the fractional coordinates (the blue point) is simple interpolation weighted by the distance to each lattice point.
constexpr float lerp (float a, float b, float t);
float
interpolate (const float values[2][2], vector2f frac)
{
auto y0 = lerp (v[0][0], v[0][1], frac.x);
auto y1 = lerp (v[1][0], v[1][1], frac.x);
return lerp (y0, y1, frac.y);
}Acquiring Randomness
A tried and true approach is to use a pre-populated array of `random' values with a known distribution and a second pertubation array of offsets. The low-order bits of the lattice coordinate is used to index into the pertubation array, which is used to index into the random values.
I utilise the integer mixing function of a keyed hash (Murmur2 in my implementation). Given a seed, and the lattice coordinates, I can divide the output by the maximum to get a uniform real.
Warning:
If using the mixing function approach pay particular attention to any emergence of directional artefacts arising from your choice and usage of mixing function.
Evaluation
Given that the source of randomness here is truely uniform there is a risk that the generated noise will not have the gradual transitions that coherent noise is known for.
However this approach has high performance, gives direct control over the value distributions, and can often be 'good enough' for many use-cases (especially when used as a basis for fractals).

Perlin Noise
Rather than assigning scalar values to lattice points Perlin noise assigns n-dimensional vectors (the red lines).
Evaluation for a coordinate is by computing the difference of the input coordinate and the lattice coordinate, then the dot-product of this difference with the lattice point’s vector. Interpolation of these values is performed as per value noise.
Randomness can be generated in much the same way as value noise. Simple extensions include: * listing n-d values in the value array * repeated perbutation indexing for each dimension * repeated integer mixing for each dimension
The algorithm gives a far more gradual change than value noise, at the cost of increased computational complexity.

The cost of scaling Perlin noise to higher dimensions becomes prohibitive quite rapidly, with complexity of O(pow(2,n)). Simplex noise was developed partially to counter this issue.
Worley/Voronoi Noise
Stepping away from lattice noise, Worley noise is derived from a distribution of points in n-dimensional space.

The value for each query is the distance from the query to the nearest point.

Extensions
Evaluation is not restricted to the closest point. We can generalise the formula as a linear combination of distances to the nearest n points, commonly written as Fn (eg, F2 for second distance, F1-F2 for first minus second distances).
The distance function is not restricted to Euclidean metrics. Manhattan and Chebyshev distances are popular alternatives, generating the appearance of edges tending along the axes.
Interpolation
Value and Perlin noise make extensive use of interpolation across the pow(2,n) points.

Most commonly cubic and quintic polynomials are used (given their specification in the two Perlin papers).
Simple linear interpolation is sufficient for some purposes and gives some amount of evaluation speedup, but tends to display obvious axis aligned artefacts. The extreme of truncated 'interpolation' is all but useless because of it’s obvious grid structure.
Cosine interpolation allows a smooth transition and has interesting gradient properties, but can incur a far higher runtime cost.
Interpolation comparison, with 8 octaves of Perlin FBM
- linear
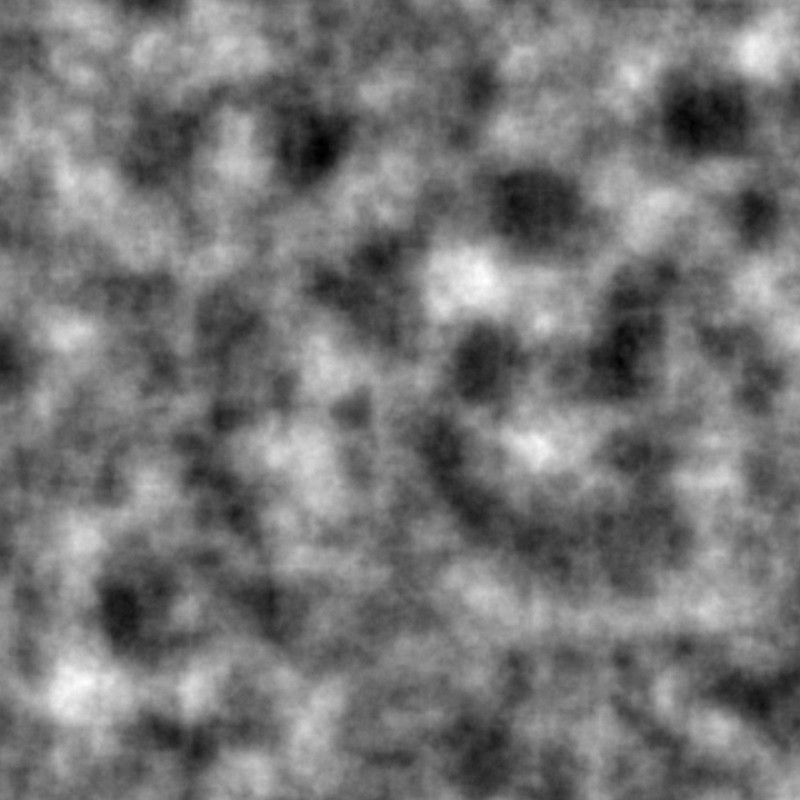
- cubic

- quintic

- cosine

While interpolation functions are an interesting (and excessive) parameter, they don’t appear to increase performance greatly, while potentially introducing significant grid artefacts.
Fractals
The basis functions above could be useful sucessfully by themselves for many simple operations, but their power is greatly increased by combining success evaluations as a fractal. The concept is to provide both high frequency (detail) and low frequency (structure) by summing successive iterations with increasing frequency and decreasing scaling.
- octaves
- iteration count
- lacunarity
- per-octave position scaling
- gain
- per-octave position scaling
I will also reference parameters named 'frequency' (the initial lacunarity) and 'amplitude' (the initial gain) for implementation flexibility.
Fractional Brownian Motion
Fractional Brownian Motion (abbreviated as FBM) is the simplest and most well known fractal. It is often conflated with the Perlin (or other) basis functions given its near universal promotion.
Single Perlin octaves used in FBM noise
- 1

- 2

- 3

- 4

- 5

- 6

- 7

- 8

As with many fractals, FBM evaluates the basis function for a set number of octaves. Each iteration has an increasing multiplier for the evaluated point position, and a decreasing multiplier on the effect of each octave. Both are applied for each evaluation of the basis function, whose results are summed.
float
fbm::eval (point2f p) const
{
float total = 0;
float scale = m_amplitude;
p *= m_frequency;
for (unsigned i = 0; i < m_octaves; ++i) {
total += m_basis (p) * scale;
p *= m_lacunarity;
scale *= m_gain;
}
return total;
}Warning:
One gotcha in the above implementation is amplification of results near the origin. Given successive evaluations with one input coordinate very close to zero, multiplicative frequency scaling (through lacunarity) will leave the input coordinate very close to it’s original value. Simple fixes include octave dependant seeds, and a small constant input coordinate offset per octave.
Evaluation
Value basis across FBM octaves octaves
- 1
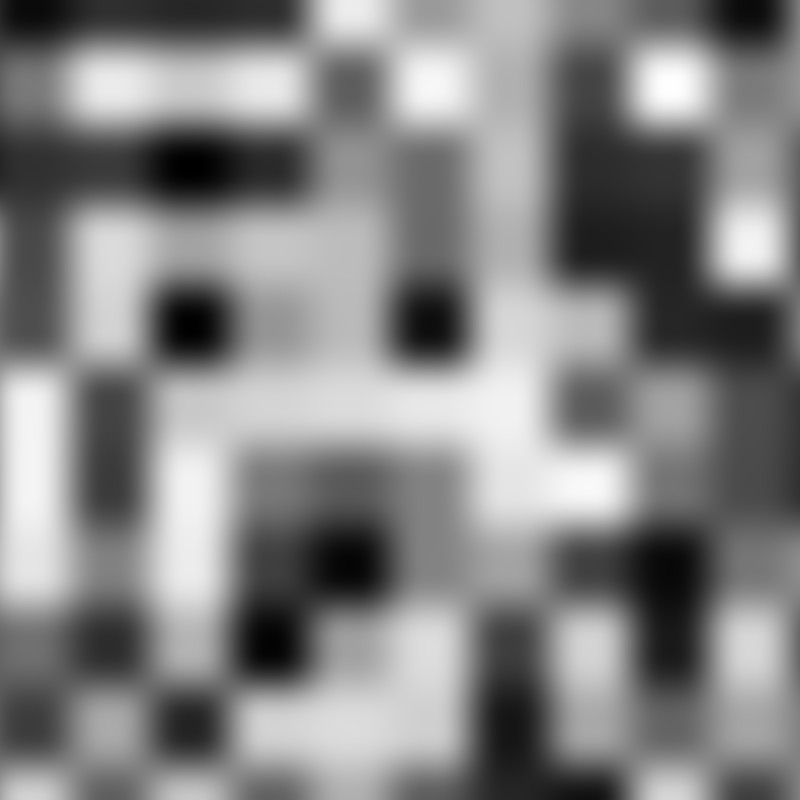
- 2

- 3

- 4

- 5

A well defined grid from the initial octave is quite obvious for the first 4 octaves. After which the higher frequency layers soften, but never quite eliminate, the grid artefacts.
This isn’t necessarily a negative for some applications, but can be exceedingly difficult to remove in post-processing.
Perlin basis across FBM octaves
- 1

- 2

- 3

- 4

- 5

The base layer is much smoother than value noise, and the structure does not alter significantly after perhaps 2 octaves. Indeed, Perline noise can appear quite homogenous when compared to value noise at similar scales.
Worley basis across FBM octave
- 1

- 2

- 3

- 4

- 5

Worley noise appears vastly different to other lattice noise.
Additional visual detail is greatly diminshed after 4 octaves. I tend to select at least 2 octaves less Worley noise than Value or Perlin.
Evaluating Worley noise can be quite expensive, depending on your implementation. Particularly if using higher arity variants (eg, f2-f1, f4).
Musgrave’s Models
There are a number of common fractal noise algorithms, specifically designed for terrain, written by Ken Musgrave.
Ridged Multifractal, Hybrid Multifractal, and Heterogenous terrain are the typical examples that can found scattered around the internet. These are all described in detail in the book `Texture and Modelling: A Procedural Approach'.
Turblence
Offset terbulence is a simple extension to any noise function where the queried position is randomly perturbed; commonly by a secondary coherent noise function.
float
turblence::eval (point2f p) const
{
vector2f offset {
m_perturb[0] (p),
m_perturb[1] (p)
};
return m_data.eval (p + offset * m_scale);
}The simplest method is to instantiate an additional basis function for each dimension and offset the query using these values.
Offset turblence with 8 octave FBM perlin
- 00%

- 10%

- 20%

- 30%

- 40%

- 50%

Experimenting with parameters can prove interesting, with values well above 100% displaying an unexpected effect.
Postprocess
Coherent noise routines don’t stop here. Many applications, such as terrain generation, greatly benefit from post-processing.
Normalising the output to unit values can simplify display and further processing.
- normalisation
- guaranteed bounds, but probabilistic.
- not amenable to infinite planes
- ocean offset
- erosion models
- gradient colours
Conclusions
Implementing your own coherent noise routines can be an interesting exercise.
While it is as important as ever to carefully evaluate the problem you are attempting to solve, a simple Perlin FBM implementation will get you a long way.